Meaning Memory Enters Beta
Structured cognition for enterprise multi-agent fleets, now in licensed private beta. A five-dimensional memory architecture productized as a self-host engine your data stays inside.
By Clinton Stark • launch, beta, announcement
Today we are opening the doors on the Meaning Memory Engine, a five-dimensional memory architecture for enterprise multi-agent fleets. This release is licensed private beta: direct distribution, NDA, and customer-self-hosted. Your team runs the engine inside your own infrastructure. Your memory data stays yours and remains on-prem.
Best fit for teams already running multi-agent workflows in production, including fleets built on OpenClaw, Hermes, or other emerging multi-agent frameworks. If you operate fleets at scale and need a memory substrate that holds up under audit, Meaning Memory provides the encoding fidelity, scope isolation, and audit-grade provenance your operators expect.
Why we built this
Meaning Memory leads with encoding compliance: the question of which signals actually become memories in the first place. Get encoding right and retrieval works because the substrate is sound. Get encoding wrong and even the cleverest retrieval ranks the wrong things.
We solve encoding with a dual-write architecture. An agent-deliberate path captures high-fidelity narrative memories the agent explicitly flags. A passive extractor path captures everything else as atomic memories. A Significance scorer arbitrates the merge. The result: near-zero encoding miss rate alongside high-fidelity narrative coverage. We call this dual-write encoding compliance.
At the center is Significance, the dimension closest to how human memory actually works. Not every interaction matters equally; humans encode and retain disproportionately what carries weight, and Meaning Memory makes that judgment explicit and tunable. Each entry carries a significance score that drives trimming under budget pressure, supports optional decay curves inspired by human-memory research (exponential, step, logarithmic, or off, operator-tunable), and powers supersede flow when newer evidence arrives. The engine forgets gracefully, updates honestly, and surfaces what matters.
Asymmetry ships as a first-class dimension. Multi-agent fleets need to know whose perspective each memory carries, and trust gradients need to flow through retrieval ranking automatically. Asymmetry is observable on every entry and composable in every query.
What is in the beta
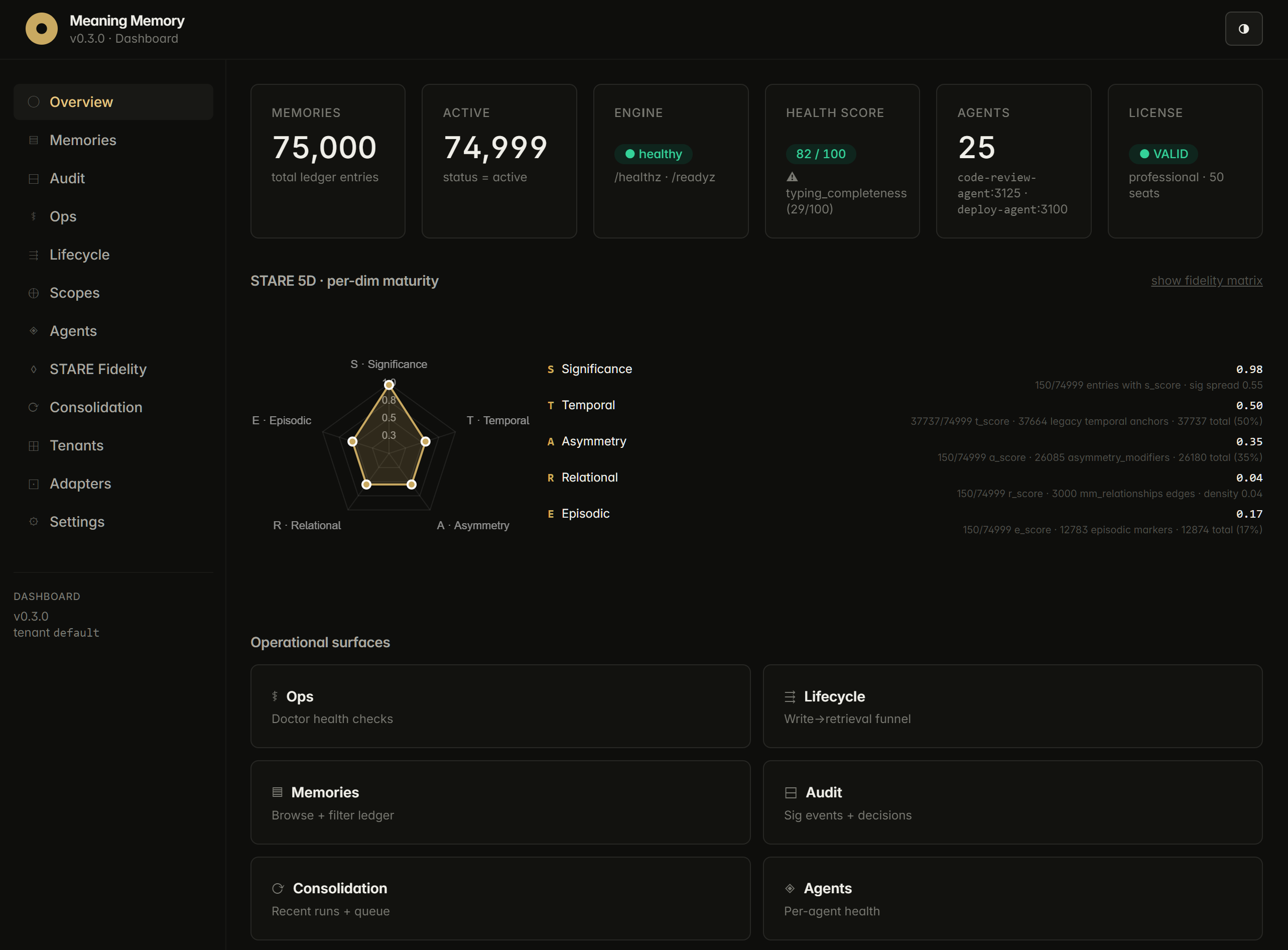
STARE 5D Core, our five-dimensional cognitive architecture, ships across all five dimensions with per-dim maturity that matches the customer-kit capability matrix: Significance and Temporal at GA, Relational as typed edges plus 1-hop filters and provenance (multi-hop traversal remains a research track pending further benchmark validation), Asymmetry modifiers at retrieval with the A-dim scorer in Phase 1 beta on Postgres, and Episodic episode summaries stable with narrative clustering beta and opt-in. Each dimension carries an independent score and is independently queryable. Dimensions compose at compile time (additive richness boost) and at retrieval time (multiplicative asymmetry scale).
STARE is the actual ranking algebra, observable in every retrieval, with the audit trail your CTO and compliance officer can verify directly.
Highlights:
- Procedural Memory Layer. A three-way memory_type taxonomy (
semantic/episodic/procedural) with type-aware compilation rules. Procedural memories carry capabilities and how-to knowledge, are exempt from significance-based trimming, and emit in a dedicated Capabilities section at the top of the compiled memory snapshot. Your agent keeps its skills under budget pressure. - Memory Seeding (v0.1). Bulk-import product catalogs, runbooks, procedures, and reference documentation via the
meaning-memory seedCLI ormm_bulk_rememberMCP tool. Your agents start with structured context instead of cold ledgers. Per-tenant scoping, automatic STARE scoring on ingest, full provenance trail per imported memory. - Auto-STARE with bundled local components. Local embeddings (BGE-M3) and a bundled distilled Significance scorer ship in the wheel and run on CPU. No embedding-provider account, no model selection for the baseline. Richer atomic-memory extraction and full STARE 5D scoring during consolidation use your configured LLM provider (Anthropic, OpenAI, Mistral, Ollama-local, or any handler you wire), so the cognitive layer keeps pace with whichever model you trust.
- Dual-backend architecture. Customers choose between a File-based backend (Markdown-native, agent-isolated, simple backups, air-gap friendly, single-host pilots) or a PostgreSQL backend (multi-tenant fleets at scale, SQL audit, transactional consistency).
- Verifiable provenance. Every memory entry carries a five-step provenance trail back to its source artifacts. Immutable hash-chain audit. Per-tenant audit events. SOC 2 roadmap published.
- Web admin dashboard with the STARE 5D radar, Memory Health Score, per-agent breakdown, and the “Why This Memory?” composition panel for operator debugging.
- MCP server for native integration with Claude Code, Cursor, OpenClaw, Hermes, and other MCP-aware agents.
- Episodic narrative rendering (beta). Deterministic narrative outlines in Phase 4 compile when Mode B clustering is enabled (
MM_E_CLUSTER_MODE_B_ENABLED).
The customer kit ships with INSTALL, DEPLOYMENT, OPERATIONS, SECURITY, COMPLIANCE, SUPPORT, and TERMS as separate documents, plus a 60-second make demo that boots Postgres, installs the wheel, seeds memories across three agents, and proves scope isolation in five steps.
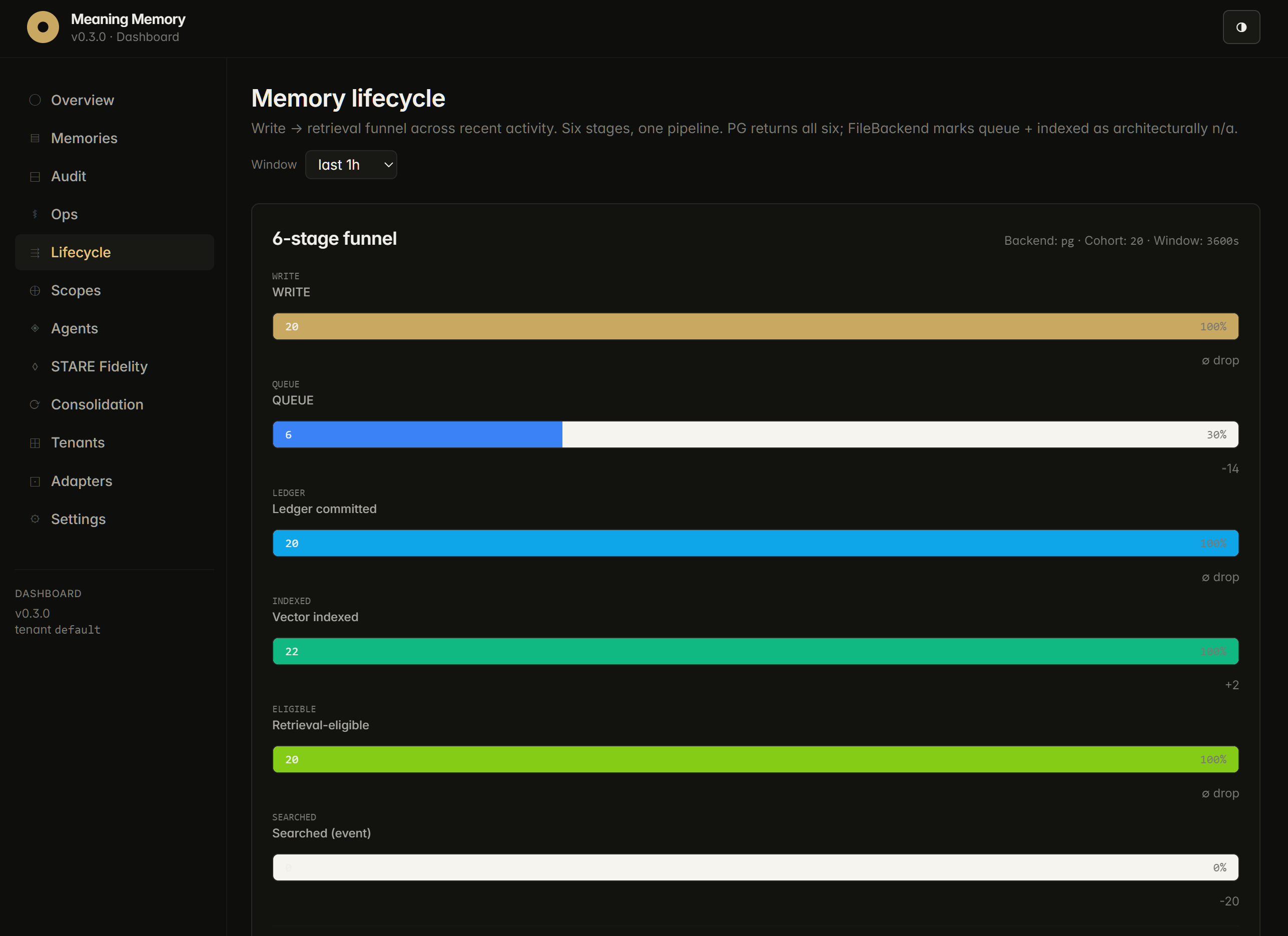
Early scale numbers
We are publishing the first scale measurements as we run them. Latest results of our internal tests:
- At 10,000 entries, the deterministic pgvector HNSW scale harness achieved 100.0% recall@5 with 2.4 ms p50 retrieval latency. HNSW index built in 4.2 seconds; sampled peak container RSS during index creation was 152.9 MB.
- At 100,000 entries, 100.0% recall@5 with 16.0 ms p50 retrieval latency. HNSW index built in 520.7 seconds; sampled peak container RSS was 203.6 MB.
- Synthetic corpora are seed-deterministic and reproducible byte-for-byte at both scales.
- Pass 1 isolates corpus reproducibility and pgvector HNSW retrieval behavior; 1M, 10M, multi-replica, and concurrent-agent measurements are not included yet. Subsequent passes ship in the following weeks.
What beta means
This is Stage 1 private beta: license-gated, direct distribution, NDA. We are inviting the first cohort of design partners now: enterprise teams running multi-agent workflows in production who want to shape what Meaning Memory becomes. Distribution is direct from us to you, license-activated, with SHA-anchored wheels. You install in your own infrastructure.
If you are running multi-agent workflows in finance, legal, healthcare, customer operations, or developer tooling, and you are ready for a memory layer designed for production agents, we want to hear from you.
Talk to us
Beta access is by introduction. The fastest path is the Request Access form: tell us what your agent fleet does today, where memory is the most interesting problem, and a bit about scale. Prefer email? [email protected] works too.
The technical reading list, if you prefer to dive deep before reaching out:
- Use Cases: Five concrete scenarios where structured cognition changes business outcomes.
- Architecture: The high-level pipeline.
More coming. Thanks for being here at the start.
Clinton Stark
Founder, Product Manager
Meaning Memory